11 min to read
From Chaos to Control: Relationship-Based Access Control (ReBAC) with OpenFG
Taming complex permissions in your application without losing your mind

Authorization versus real world
Usually at early stage of system evolution there are many more important features then one concerning permissions. Business domain is getting bigger and bigger, features incessantly building up in backlog - who have time to think how are we going to hand accessing logic:

Then all the sudden, here’s come new business requirement
Hey guys, remember those great features we had created lately? Yea, we need to limit access to those a little bit for some users
Project study
It will be easier to go through authorization topic when discussing some system by example. Let’s imagine very simple one in which we have some user’s accounts with simple permissions to documents (read, write, owner).
At first, with that straight forward model we just collect documents connected to some account, that’s it, not much authentication there.
Folders
Let’s introduce folders (surprise huh?). Requirement is fairly simple, each document might be contained inside folder, each folder might be nested into another folder as well.
That’s makes it bit harder, now, we need to introduce some hierarchy calculations, which might be tricky to implement correctly (in relational databases for example). Now, we not only just checking direct permissions, we need to investigate each parent object:
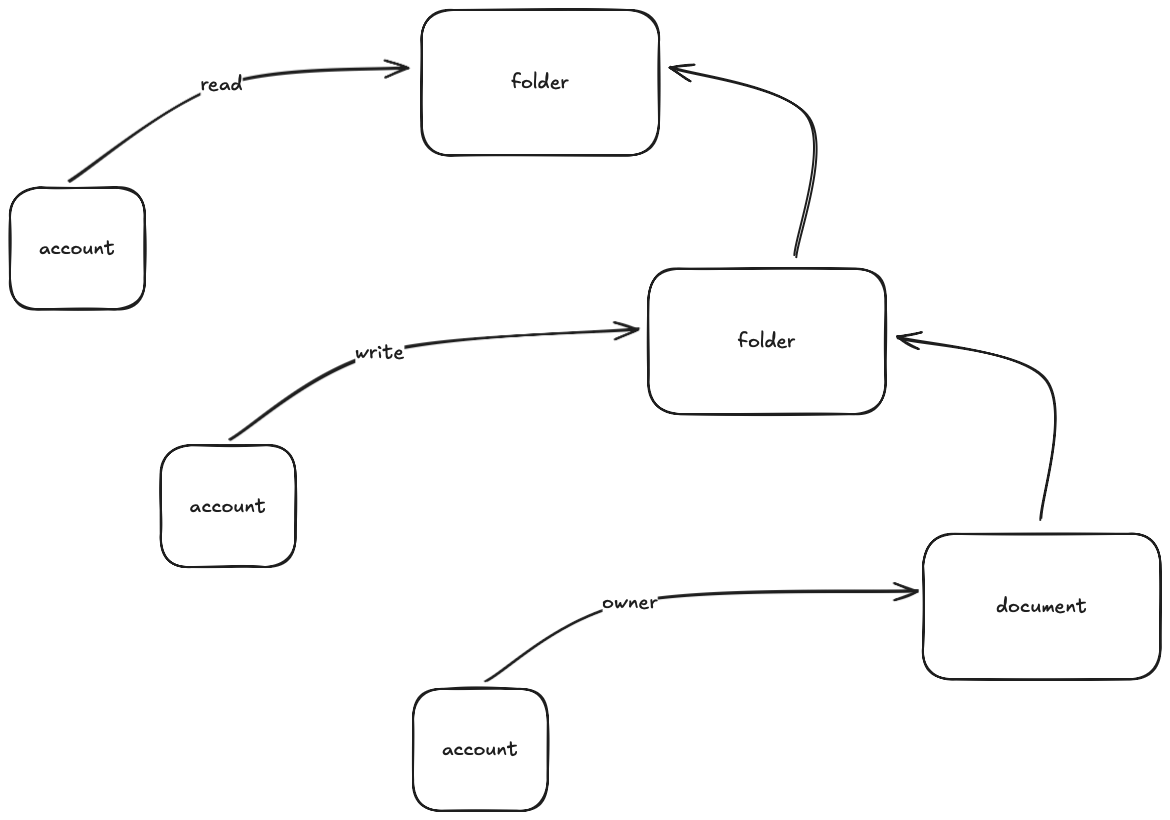
Account groups
Just when you thought you had it figured out with folders, account groups arrive. Now, to check a permission, you have to answer: “Is the user a member of any group (or any parent group of that group) that has access to this document (or any of its parent folders)?”:
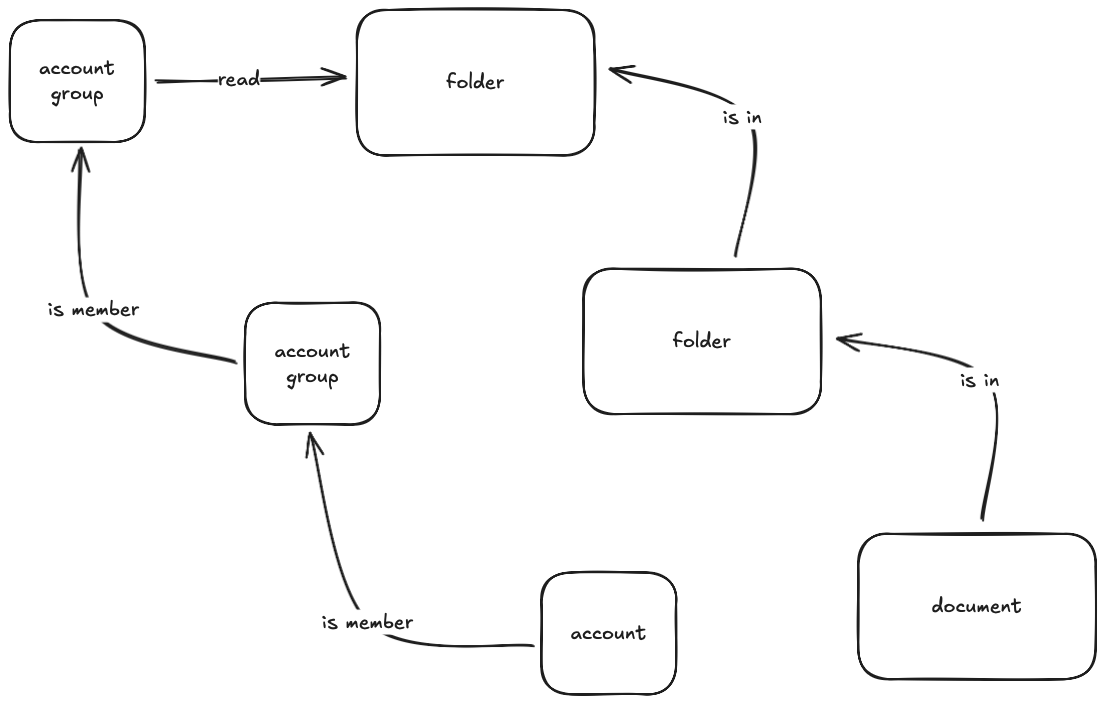
You now have to traverse two hierarchies: the document’s folder structure and the user’s group memberships. This quickly becomes a performance bottleneck and a maintenance nightmare.
ReBAC for rescue

If the previous sections gave you a headache, you’re not alone. Trying to manage those tangled permissions with traditional methods can hurt, specially at scale.
This is where a different approach rides in to save the day: Relationship-Based Access Control (ReBAC).
So, what is this magic? ReBAC shifts the focus from what a user is (their role) to how they are connected to a resource (their relation). The permission isn’t just a static flag; it’s derived from the graph of relationships in your system.
ReBAC elegantly solves our folder and group nesting problems.
The question
“Can this user access this document?” is no longer a series of complex, recursive queries.
Instead, it becomes a simple graph traversal: “Is there a path of relationships connecting this user to this document with the can_view relation?”
Zanzibar and OpenFGA

Sounds great, but that’s just theory. How do we actually build this without reinventing a distributed graph database from scratch?
This is where we can learn and gain from others. Back in 2019, Google published a paper called Zanzibar: Google’s Consistent, Global Authorization System. It detailed the system they use internally to handle authorization for their internal services, including Google Drive and YouTube. It’s the blueprint for ReBAC at a massive scale.
While we can’t just plug into Google’s internal system, Zanzibar’s paper inspired tools and systems implementing same ReBAC principles. One we are going to consider is: OpenFGA. It’s an open-source project, now part of the Cloud Native Computing Foundation (CNCF).
OpenFGA gives us the concrete tools to turn theory into practice. It provides:
- A modeling language: Special language for defining authorization model. This is where we’d define our document, folder, and user types, along with the relationships between them like owner, parent, and member.
- A database driver for tuples: An implementation for storing our relationship data (called “tuples”).
- An API for checks: A fast API to ask the crucial question: Can user:bob view document:secret.doc? OpenFGA traverses the graph of relationships for us and returns a simple true or false.
Getting started
Let’s start with our openFGA model:
model
schema 1.1
type user
type group
relations
define member: [user, group]
type folder
relations
define parent: [folder]
define reader: [user, group#member]
define writer: [user, group#member]
define can_read: reader or writer or can_read from parent
define can_write: writer or can_write from parent
type document
relations
define parent: [folder]
define reader: [user, group#member]
define writer: [user, group#member]
define can_read: reader or writer or can_read from parent
define can_write: writer or can_write from parent
This is the heart of our system. We’ll update our model to include reader and writer roles on both folders and documents. Crucially, we’ll define that writer also implies reader, and that permissions are inherited from parent folders.
Let’s break it down:
define reader: [user, group#member] means that reader might be either some user, but also any member of users group.
can_read on a document:
- reader or writer: A user can read if they are a direct reader OR a writer of the document.
- …or can_read from parent: A user can also read the document if they have can_read permission on it’s parent folder. This recursively handles inheritance.
Deployment
Now that we have model, the next logical question is: where does it run? The answer depends on your environment, but the OpenFGA project provides flexible options for every stage of development.
For more information about it best place would be check open fga documentation. For our needs we will start with simple docker image:
docker run -p 8080:8080 openfga/openfga run
Setup
For communication with openFGA we will use openFGA CLI tool, you may install in you computer (I will use brew, but you might find more options here)
brew install openfga/tap/fga
With the CLI installed, we can create our store. A store is a entity that contains authorization data, models and relationship tuples.
Let’s create the store with our model:
fga store create --name docs-system --model model.fga
This will return a unique ID for your new store and authorization model, those will be needed for all future interactions.
{
"store": {
"created_at":"2025-07-14T21:43:00.1832Z",
"id":"01K05E88TPAV7GWYBDCBZJQ6JA",
"name":"docs-system",
"updated_at":"2025-07-14T21:43:00.1832Z"
},
"model": {
"authorization_model_id":"01K05E88TZ4GCDDF190RQN3A7N"
}
}
Adding data and checking permissions
Now for the exciting part. Let’s add some relationship tuples to our store and see the authorization model in action.
First, let’s create a group called hr-team and add user:anne as a member:
fga tuple write --store-id <store-id> user:anne member group:hr-team

Next, let’s grant the members of hr-team group reader permissions on the document:cv.pdf:
fga tuple write --store-id <store-id> document:cv.pdf reader group:hr-team#member

Now, the moment of truth. Let’s check if user:anne can read document:cv.pdf. We’ll use the fga check command:
fga query check --store-id <store-id> user:anne can_read document:cv.pdf
OpenFGA will traverse the relationships and return the result:
{
"allowed": true
}
Success! Even though we never directly granted user:anne permission to the document, OpenFGA correctly inferred the can_read permission through her membership in the hr-team group. This is the power of ReBAC in action.
Querying for UIs and Audits
Beyond simple checks, a critical function of an authorization system is to answer two key questions:
- “What can this user access?”
- “Who can access this resource?”
OpenFGA answers these with list-objects and list-users.
Listing Objects for a User
To build a UI showing all the documents user:anne can read, you would use list-objects:
fga query list-objects --store-id <store-id> user:anne can_read document
This returns a simple list of object IDs, perfect for populating a user’s dashboard:
{
"objects": [
"document:cv.pdf"
]
}
Listing Users for an Object
To see who has can_read access to document:cv.pdf for an admin panel, you use list-users:
fga query list-users --store-id <store-id> --object document:cv.pdf --relation can_read --user-filter user
This returns all the users with that permission:
{
"users": [
{
"object": {
"id":"anne",
"type":"user"
}
}
]
}
Although above query examples might be enough for some usages, it’s very important to get acquainted with searching patterns for production use here.
Beyond the Basics: Production Considerations
We’ve covered the fundamentals of OpenFGA, from modeling to querying. While the CLI is an excellent tool for learning and testing, you’ll use an SDK in your application code. OpenFGA offers a rich ecosystem of SDKs for various languages, allowing you to integrate authorization checks and queries seamlessly into your services.
However, the most critical consideration when moving to production is performance. While OpenFGA is designed to be extremely fast, a poorly designed model or an inefficient query pattern can still lead to latency. Always consult the official documentation to understand the trade-offs and best practices for your specific use case. Planning for performance from the beginning is key to a successful deployment.
Deeper Dive: Understanding the Modeling Language
Our model worked perfectly, but it’s worth taking a moment to understand a critical piece of syntax: group#member.
When we defined the reader relation on our document type, we wrote:
define reader: [user, group#member]
This line is the key to making group permissions work. It tells OpenFGA that the reader relation can be assigned to two kinds of subjects:
- A
user(e.g.,user:anne) - The result of the
memberrelation on agroup(e.g.,group:hr-team#member)
This is why our tuple document:cv.pdf reader group:hr-team#member was valid. We weren’t assigning the reader role to the group itself, but to its members.
A Common Pitfall: group vs. group#member
What if we had written define reader: [user, group] instead? In that case, the tuple document:cv.pdf reader group:hr-team would be valid, but a check for user:anne would fail. Why? Because user:anne is not the same thing as group:hr-team. OpenFGA wouldn’t automatically know to look inside the group for members. The #member syntax is the explicit instruction that connects the reader relation to the member relation.
Beyond Unions: Intersections and Exclusions
The OpenFGA modeling language is surprisingly powerful. While our model only uses unions (the or keyword), you can also define more complex relationships:
- Intersection (
and): You could define asuper_adminwho must be amemberof theadmingroup AND thesecuritygroup. - Exclusion (
but not): You could grantcan_viewto allemployeesBUT NOTinterns.
These operators allow you to build highly granular and expressive authorization models that can adapt to complex business rules.
Wrapping Up
And there you have it! We started with a tangled mess of permissions and ended with a clean, clear, and powerful authorization model. By thinking in terms of relationships, we were able to tame the complexity that often bogs down applications as they grow.
ReBAC and tools like OpenFGA aren’t just for massive companies like Google. They provide a practical, scalable, and surprisingly intuitive way to handle permissions for any project. So next time you feel that authorization headache coming on, remember the power of the graph. Happy coding! 🫡
Comments