14 min to read
What did I learn during 2024 advent of code

What I Learned During the 2024 Advent of Code
Advent Of Code is an advent calendar of small programming puzzles created by Eric Wastl. Each day, from December 1 to 25, you get new puzzle with increasing difficulty.
I have participated in a few previous editions, usually as a fun way to try different programming languages or spend time with my brother in a productive way (though I’m not sure he enjoyed it as much as I did 😂).
This year I changed it, and started seriously from day one with C# and ambitious plan of finishing it. Here’s my repository.
Whole advent was great fun, and I think that during that experience I have learned few things that you may find interesting as well.
Spans

You are probably already familiar with Span, a type that was introduced in c# 7.2, but just as quick reminder:
Span is designed to represent a contiguous region of arbitrary memory in type-safe and memory-safe way. This means that, unlike arrays and other collections that are containers of data allocated on the heap, it provides a lightweight view of existing data (a contiguous region).
Views
First great usage that pumped pretty much everywhere in advent of code puzzles was scanning and cutting arrays or matrixes over and over again. Let’s examine simple example where we do have some input array:
string[] input = GetInput();
Now imagine we have some logic in loop, that will search up this array until some finally condition:
while(true)
{
string[] view = LookUp(input); //some array cutting logic - like input[i..j]
if(IsSatisfied(view)) break;
}
That works great, but it will allocate a brand new array on each loop iteration, even when we just need a way to create a view window rather than recreating the data.
This is exactly when Span shines:
while(true)
{
Span<string> view = LookUp(input);
if(IsSatisfied(view)) break;
}
Same code, no allocations—magic!
Searching
Although span used as views can already have performance impact (specially in memory usage - decreasing GC pressure), we can also benefit much by using all extensions methods that were created for them.
In many puzzles, we had to scan through some input maps in order to find out where we should move, etc.
Input map could look like:
###########
#......#E*#
#.##*#*#.*#
#.S#*#...*#
#......####
###########
Where S is start position, E is end position, * symbols are trees, # walls and finally . is regular floor that we can move though.
Based on task we need to fulfill, sometimes it might be useful to search though map, looking for some character.
For example, having row data, we would like to find out next position of anything other then walls (so floor or tree).
Having input as char array, we need to iterate through data in some way, for example using LINQ:
var startingIndex = 3; //some index
var floorOrWall = input
.Where((x, index) => index >= startingIndex && x is '.' or '*')
.Index()
.Select(x => x.Index)
.DefaultIfEmpty(-1)
.FirstOrDefault();
or using simple loop:
var startingIndex = 3;
var found = -1;
for (var i = startingIndex; i < input.Length; i++)
{
if (input[i] is '.' or '*')
{
found = i;
break;
}
}
but why bother if we could utilize span methods. First, we do take another window from starting index:
var startingIndex = 3;
var subWindow = input[startingIndex..];
Then we can take index of given characters and calculate final result:
var subIndex = subWindow.IndexOfAny('.', '*');
var found = subIndex == -1 ? -1 : subIndex + startingIndex; //if -1 then not found, otherwise add startingIndex as we were looking in sub window
Span solution will be very similar in terms of performance as loop (no memory allocation), and much better then LINQ:
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|------- |-----------:|----------:|----------:|-------:|----------:|
| Linq | 857.204 ns | 2.7199 ns | 2.4111 ns | 0.0324 | 272 B |
| Loop | 1.585 ns | 0.0022 ns | 0.0018 ns | - | - |
| Span | 1.982 ns | 0.0049 ns | 0.0043 ns | - | - |
Aside from this method, we also have many other very helpful ones:
IndexOfAnyExcept- Searches for the first index of any value other than the specified valueIndexOfAnyInRange- Searches for the first index of any value in the range betweenIndexOfAnyExceptInRange- Searches for the first index of any value outside of the range between andLastIndexOf*methods equivalents.
Frozen collections

.NET 8 has introduced brand new collections in System.Collections.Frozen namespace. We got:
FrozenDictionaryFrozenDictionary<TKey, TValue>FrozenSetFrozenSet<T>
In nutshell, frozen collections are immutable (once created you cannot modify them), read-only, thread safe and optimize for access performance.
The price we need to pay occurs during creation; it has a relatively higher cost to create than the normal implementation. This is why it should be used in scenarios when created infrequently (for example on application startup), but used very often.
Performance improvement
We know theory, but how does this reflect on performance of implementation?
I did used it in few places of this year advent of code, it did specially good in day 22. In that puzzle, we had to outsmart the monkey buyers on the Monkey Exchange Market. My solution required quite a lot lookups in array of dictionaries:
int CalculatePrice(IDictionary<Key, int>[] dictionaries, Key key)
{
return dictionaries.Select(x => x.GetValueOrDefault(key, 0)).Sum();
}
Those dictionaries were created once, and then just used for lookups as above. This is where frozen collection could be helpful. Change is easy as changing one line in method that create those dictionaries:
IDictionary<Key, int> CreateDictionary()
{
Dictionary<Key, int> result = [];
//some logic
- return result;
+ return result.ToFrozenDictionary();
}
Just by changing this single line in my algorithm, process finishing faster by ~28%, which is huge comparing to cost of implementation.
Regex

As we all know:
Some people, when confronted with a problem, think
“I know, I'll use regular expressions.” Now they have two problems.
quote by Jamie Zawinski
This, along with my belief that regex would always be much slower than manual, step-by-step parsing, caused me to rarely consider it (in my professional work, though this affected my approach in open-source/AoC as well).
In advent of code every day puzzle starts with parsing of input, in may be easier or little bit more complicated but it’s always there. On Day 3 we had to parse input like:
xmul(2,4)&mul[3,7]!^don't()_mul(5,5)+mul(32,64](mul(11,8)undo()?mul(8,5))
and correctly interpret all mul, do, don't calls. I have started solution by writing simple parser like:
void Parse(ReadOnlySpan<char> input)
{
var currentIndex = 0;
while(true)
{
var currentMultiplyIndex = input.IndexOf("mul(", currentIndex);
if(currentMultiplyIndex < 0) break;
currentIndex += MultiplyMarker.Length;
if(!GetNumber(input, ref currentIndex, out var firstNumber)) continue;
if(!GetChar(input, currentIndex, out var maybeComma) || maybeComma is not ',') continue;
currentIndex++;
if(!GetNumber(input, ref currentIndex, out var secondNumber)) continue;
if(!GetChar(input, currentIndex, out var maybeClosedBracket) || maybeClosedBracket is not ')') continue;
currentIndex++;
}
}
I have omitted logic for do, don't methods to keep it simple (but methodic stays the same). Methods GetNumber and GetChar are just checking the position and returning char/number.
Logic doesn’t seems to be very complected, but still, it takes time to implement and take some corner cases in consideration. After already implementing it and finishing puzzle, I wonder - how regex solution would look like, and how much slower it would be.
First of all, pattern:
do\(\)|don't\(\)|mul\((\d{1,3}),(\d{1,3})\)
It does match either:
- do()
- don’t()
- mul(x, y) where x and y are 1-3 character numbers
For best performance we will use source generation mode:
[GeneratedRegex(@"do\(\)|don't\(\)|mul\((\d{1,3}),(\d{1,3})\)")]
public static partial Regex Regex();
This also allows to investigate generated implementation which I highly recommend. It does use a lot of very clever optimization’s.
Then usage is as easy as just:
foreach (Match match in regex.Matches(input))
{
//do your logic based on match.Value
}
Code is much simpler, but how about performance? When comparing implementation required for solving puzzle I got:
| Method | Mean | Error | StdDev | Median | Gen0 | Gen1 | Allocated |
|-------- |---------:|---------:|---------:|---------:|-------:|-------:|----------:|
| Regex | 532.7 ns | 10.69 ns | 18.14 ns | 523.5 ns | 0.2365 | 0.0010 | 1984 B |
| Parsing | 200.5 ns | 3.56 ns | 3.80 ns | 200.0 ns | - | - | - |
it’s slower, that’s obvious - but still it get much faster then I would imagine, specially comparing with quite performant solution (full code can be found here).
Variance

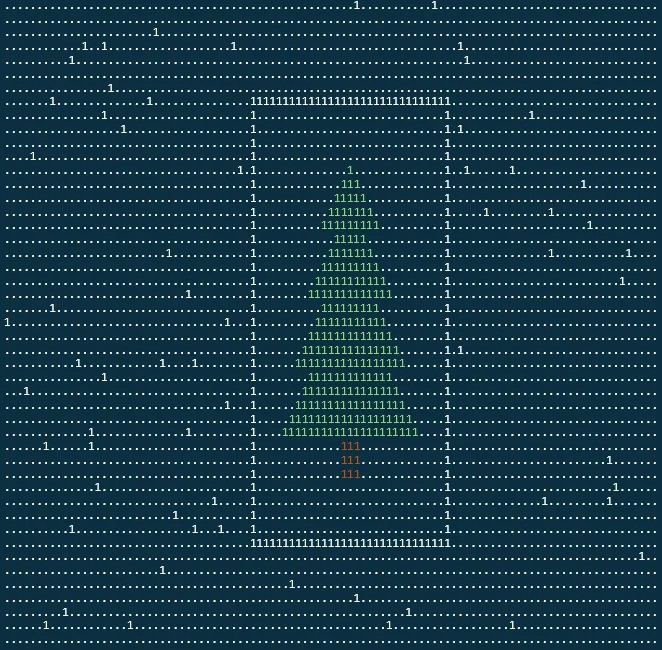
One of most interesting puzzles in this year AOC in my opinion was part 2 of day 14.
In first part, we had to calculate position of robots after given number of seconds (as input we did get initial positions and velocities).
...*. ..... ..... *....
..... -> ..*.. -> ..... -> .....
..... ..... .*... .....
After getting this part right we did faced rather unusual problem. We had to calculate fewest number of seconds after which robots would arrange themselves in form of christmas tree.
Hmmm, what? How does christmas tree should look like? Where is it suppose to be placed on canvas? How big it is? Does it have ornaments, trunk?
After initial stunned I started to wonder, what could distinguish tree, without even knowing how it should look like. My first approach was to find row in which “unusual” number of robots, would lay next to each other (creating long base of christmas tree):
*
***
*****
******* <----- this thing
*
*
hoping this shape should occur there.
It could work, but unfortunately process of searching was very long. After finding something, it didn’t really looked like tree so I had to continue with next shot, and so on and on.
Then, I just thought to use variance of all points, and this is where it clicked.
private static double CalculateTotalVariance(Robot[] points)
{
var meanX = points.Average(p => p.X);
var meanY = points.Average(p => p.Y);
var sumOfSquaredDistances = points.Sum(p => Math.Pow(p.X - meanX, 2) + Math.Pow(p.Y - meanY, 2));
return sumOfSquaredDistances / points.Length;
}
I have adjusted threshold after calculating it for first few generation and run it, searching for ones with higher value then my threshold. And voilà:
git-crypt

Since the content of Advent of Code is not licensed for reproduction or distribution without permission (including personal input data), I wondered if there was a way to keep my inputs in some encrypted format for easier use.
This is when I first encountered git-crypt (even though I could have been using it much earlier 😫).
git-crypt is a simple tool that allows you to store secrets in your public repository in an encrypted and secure way. Once configured, it is completely transparent to use—it’s as if it was never there.
All that’s required is a key (stored in a file) that is kept on your local computer (it can be shared across different projects to make things even easier). You’ll also need a .gitattributes file in your repository to specify which files should be encrypted. In my example, it looks like this:
**/*.input filter=git-crypt diff=git-crypt
This will ensure that all files with the *.input extension are encrypted.
From now on, any file with the *.input extension will be pushed to your repository in an encrypted format, with no further action required from your side.
Wrapping up
This year Advent Of Code was absolutely tons of fun, even when it kept me up until 3 a.m. 😂

It gave me the opportunity to grow as a developer, and once again, I found myself diving deep into the internet to learn new things I didn’t know before.
Thanks for reading, and I hope to see you next year! 🎄💻
Comments